Handwriting recognition
Improving recognition of handwriting with component samples
Submitted by Christoph on 20 November, 2009 - 01:58Yet another post on handwriting recognition of Japanese and Chinese characters with Tegaki. This time I want to improve recognition rates of existing models.
Recognizing basic strokes in handwriting
Submitted by Christoph on 21 October, 2009 - 23:57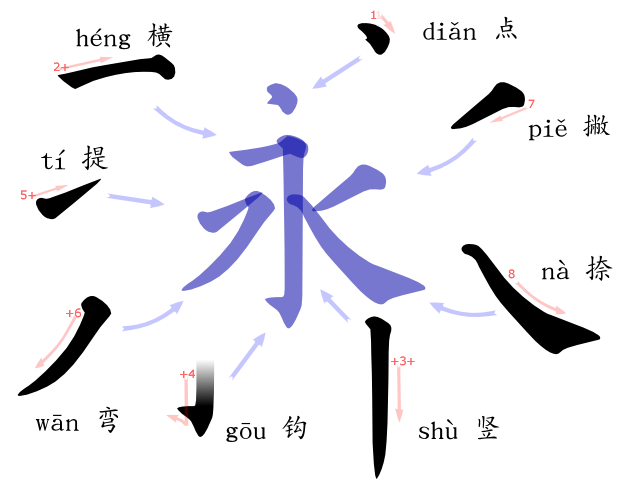
Just recently this blog has seen a post about Tegaki. It's a handwriting recognition system for Chinese Characters/Kanji, and I tried a bootstrapping process for a missing model of Traditional Chinese. Yesterday I started to think about other possibilities of Tegaki and wanted to try recognizing single strokes.
Bootstrapping Tegaki handwriting models using character decomposition
Submitted by Christoph on 7 October, 2009 - 13:28
Just yesterday, I committed a new list of character decompositions to cjklib, that was gratefully released under LGPL by Gavin Grover. While until now the about 500 entries served more as a proof of concept, we now have more than 20.000 decompositions spanning the most important characters as encoded by Unicode.
So I wanted to do something nice with this new set of data. I picked the Tegaki project which offers handwriting recognition for Kanji and Hanzi, the latter for Simplified Chinese. I remember showing off the Qt widget I developed to a friend, who then promptly drew a Traditional Chinese character that couldn't be recognized. That was of course because Tegaki (and back then Tomoe) doesn't support Traditional Chinese. Until now.
Tomoe handwriting widget for PyQt
Submitted by Christoph on 11 February, 2009 - 04:58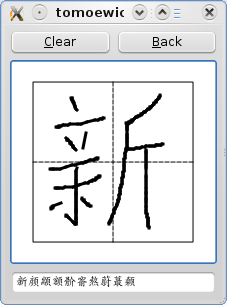
Having built Tomoe for Debian I was ready to go to develop a nice widget implementing the basic features of Tomoe giving you the TomoeHandwritingWidget.
