Recognizing basic strokes in handwriting
Just recently this blog has seen a post about Tegaki. It's a handwriting recognition system for Chinese Characters/Kanji, and I tried a bootstrapping process for a missing model of Traditional Chinese. Yesterday I started to think about other possibilities of Tegaki and wanted to try recognizing single strokes.
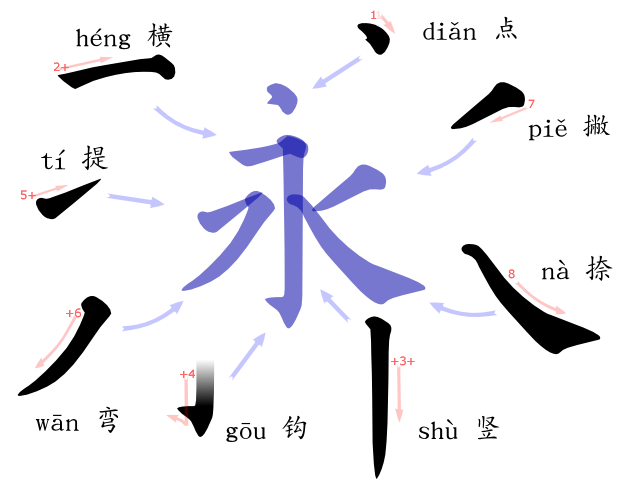
Chinese characters are drawn using a basic set of strokes that, depending on the classification, can range from 5 basic strokes to 36, or maybe more. The set of five strokes is a basic set of which all other sets can be derived.
For calligraphy it is important that a given stroke order of a character is followed, and pupils are taught the "correct" order, though it seems in daily life enough variations can be found. Stroke order becomes useful with for example mobile phones, where characters can be input using the keypad of nine keys.
So with the release of cjklib this week there is a discriptive set of stroke orders available. For example character 丞 comes with strokes ㇖㇚㇇㇒㇏㇐, or in textual form HG-SG-HP-P-N H for the abbreviated forms of their Chinese names: Henggou, Shugou, Hengpie, Pie, Na and Heng. While the descriptions are far from extensive, the system can generate stroke order information for most characters whose components are already covered.

Tegaki now comes with a different representation: stroke classes are not known, but their actual position and size are known. See the example from last post to the right. Even the stroke's starting point can be derived.
For Simplified Chinese and Japanese all important characters are covered (actually the ones from official standards). Stroke type is implict, and my current idea is to make this information visible. In the current branch of my github repository for Tegaki I am experimenting with automatically recognizing the stroke types, and up to now it seems all pretty well. All I needed to do was extract stroke models from existing data, correct some mis-aligned entries and train a model for that. As it turned out the standard recognizer did pretty bad, but luckily Mathieu, the maintainer of Tegaki, introduced a new simple recognizer lately. After a bit of C++ hacking the recognizer is now able to match a given input to a best instance of a stroke type.
My favourite example is 叚, which turns out pretty well. One row each gives the alternatives for the single strokes, the best result to the left:
㇕ (297), ㇆ (316), ㇖ (384), ㇈ (499), ㇊ (560), ㇐ (86), ㇀ (96), ㇖ (103), ㇒ (152), ㇏ (177), ㇒ (63), ㇓ (71), ㇑ (76), ㇚ (92), ㇔ (123), ㇐ (88), ㇒ (88), ㇀ (132), ㇖ (155), ㇝ (163), ㇐ (150), ㇖ (152), ㇀ (171), ㇒ (227), ㇔ (249), ㇕ (356), ㇆ (361), ㇖ (421), ㇇ (475), ㇈ (646), ㇐ (70), ㇖ (91), ㇀ (141), ㇕ (188), ㇔ (205), ㇇ (454), ㇆ (474), ㇚ (481), ㇓ (510), ㇖ (555), ㇏ (287), ㇝ (315), ㇓ (317), ㇛ (319), ㇀ (328),
It seems to me that only the third stroke did poorly. But I'll do more evaluation later.
Now I'm dreaming of a simple system of tagging characters with stroke types.
